Study RNN with 'min-char-rnn' of Andrej Karpathy(1)
25 May 2020Minimum Character RNN(min-char-rnn)
최근에 시계열 데이터 학습에 대한 공부를 하면서 RNN을 접하게 됐는데, 지원이가 RNN을 입문할 때 참고하면 좋은 모델로 min-char-rnn을 소개해줬다.
min-char-rnn은 Andrej Karpathy가 공개한 문장 생성 RNN 모델이다. 원본 코드는 여기서 찾을 수 있다. 굉장히 단순한 모델이기 때문에 만족스러운 결과가 나오지는 않지만 초심자가 RNN과 관련된 개념을 이해하고 적용하는 데에는 매우 유용하다. 저자인 Andrej Karpathy가 AI계통에서 저명한 인물이다보니 한글로 작성된 min-char-rnn 포스팅들도 쉽게 찾아볼 수 있었다.
당분간 여러 편에 걸쳐 이 모델에 대해 상세한 기술을 할 예정이다. 본 편은 min-char-rnn의 신경망 구조에 대해 서술할 것이고, 이후에 이 모델의 손실함수와 역전파에 관해 논할 것이다. 그리고 마지막에는 코드 오디팅을 진행할 것이다.
모델 세부 정보
- 신경망 구조: 순환 신경망(Recurrent Neural Network, RNN)
- 활성 함수: 하이퍼 탄젠트(tanh)
- 후처리 함수: 소프트맥스(softmax)
- 손실 함수: 크로스 엔트로피(cross entropy)
- 경사 하강법: 적응형 경사 하강법(Adaptive Gradient, AdaGrad)
순환 신경망(RNN)
데이터의 의미가 다른 데이터들과 의존성을 가질 경우, 이제까지 들어온 데이터들에 대한 기억이 존재해야 새로 들어온 것의 의미를 파악할 수 있다. 예를 들어 ‘사과를 먹는 사람’과 ‘사과를 재배하는 사람’ 이라는 두 문장이 있을 때, ‘사람’을 파악하기 위해서는 먼저 들어온 데이터들에 대한 정보를 가지고 있어야 한다.
RNN이 다른 신경망들과 가장 차별화되는 부분이 이런 기억을 가지고 있다는 것이다. RNN은 다음과 같은 구조로 이루어져 있다
아래 그림에서 노란 블록을 순환 뉴런이라고 하며, 각 순환 뉴런 사이에 전달되고 있는 h가 학습의 결과로 기억되는 정보이다.
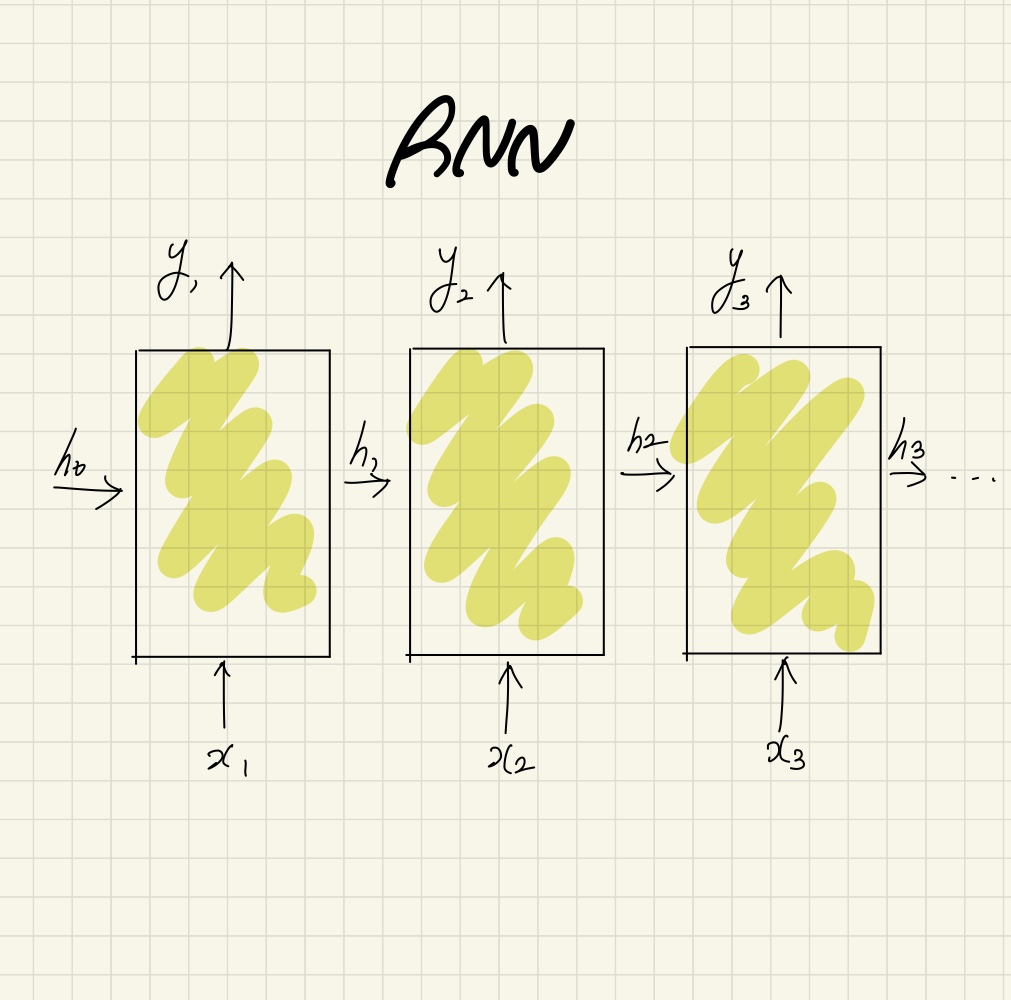
Figure1. SImple RNN
순환 뉴런
순환 뉴런은 순환 신경망에서 학습이 진행되는 단위이다. ‘min-char-rnn’에서 순환 뉴런은 다음과 같이 구성된다.
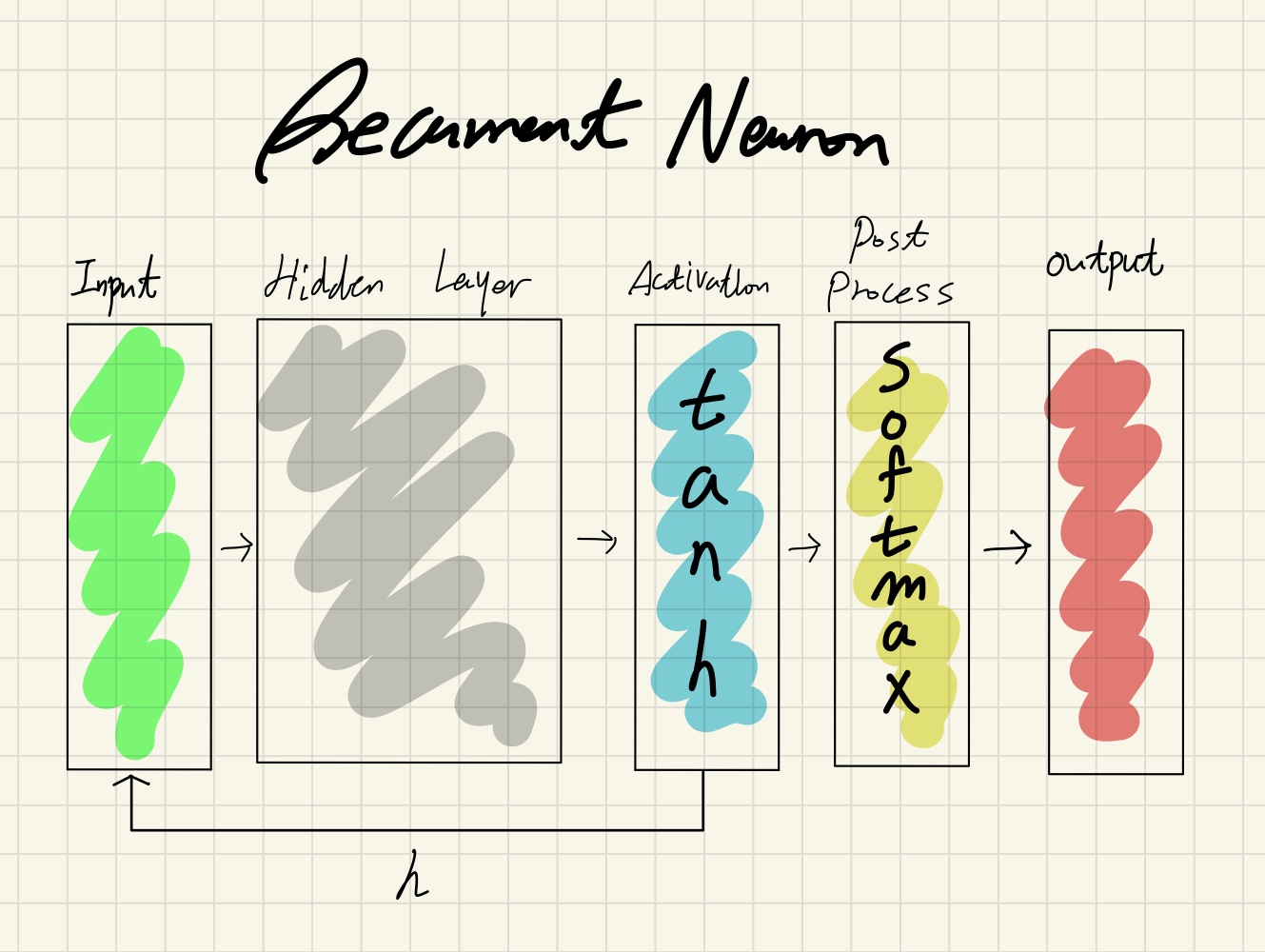
Figure2. Recurrent Neuron of min-char-rnn
입력층(Input layer)
입력층은 문자를 1차원 벡터로 치환하는 역할을 한다. 여기서는 원-핫 인코딩(one-hot encoding)이라는 방법을 사용한다.
원-핫 인코딩은 입력 집합과 같은 크기를 갖는 1차원 벡터의 원소를 모두 0으로 초기화하고, 입력값에 해당하는 인덱스만 1로 설정하는 방법이다. 가장 쉽고, 싸면서도 문자를 일대일로 벡터와 대응시킬 수 있기 때문에 자연어 처리를 처음 접할 때 가장 먼저 배우게 된다.
원-핫 인코딩의 예:
</center>

Figure3. Input layer of min-char-rnn
은닉층(Hidden layer)
은닉층은 직전 뉴런의 은닉상태인 \(h_{t-1}\)와 입력층의 출력인 \(x_t\)로 \(a\)를 계산한다. 은닉층에서는 아래 그림의 값들 중 \(w_{xh}, w_{hh}\) 그리고 \(b_h\)가 역전파를 통한 학습의 대상이다.
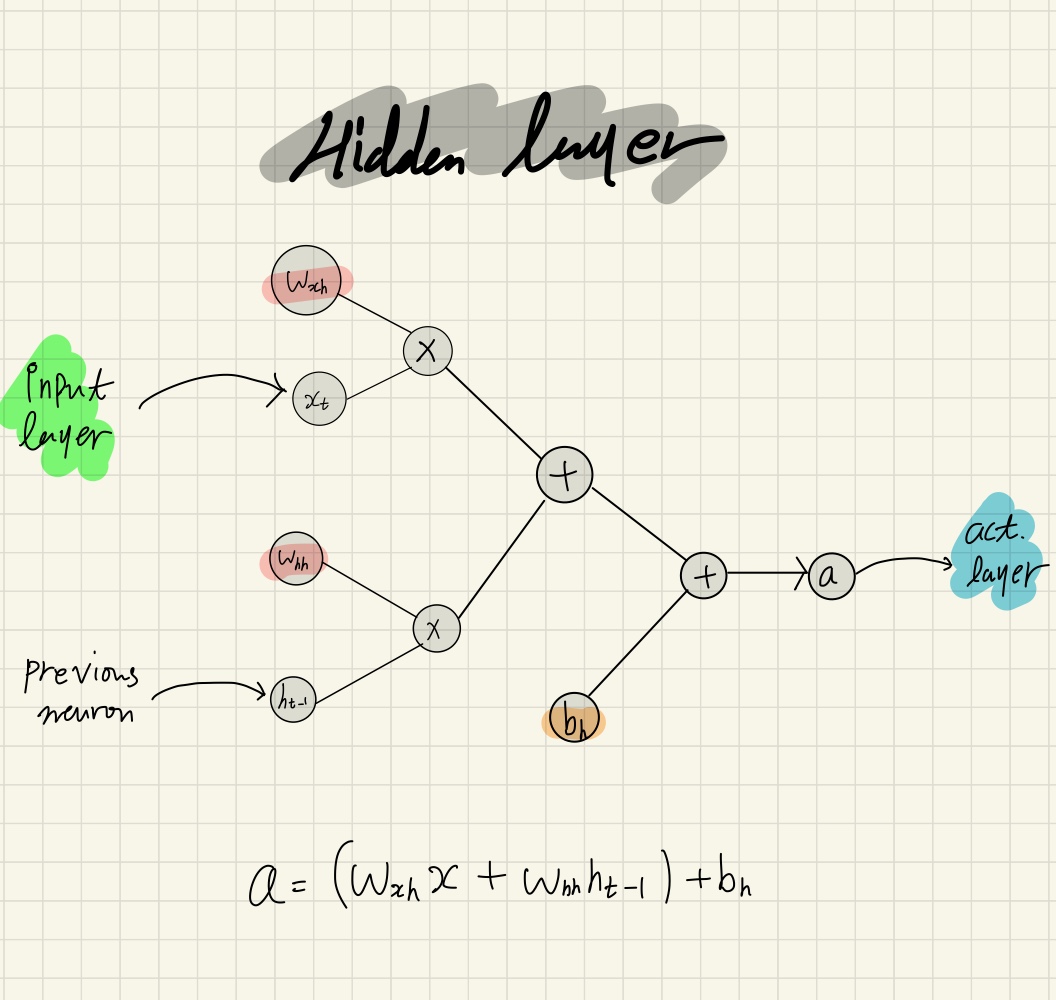
Figure4. Hidden layer of min-char-rnn
활성층(Activation layer)
활성층에서 학습할 값들은 \(w_{hy}, b_y\)이다. \(h_t\)는 다음 뉴런의 은닉층으로 들어간다.
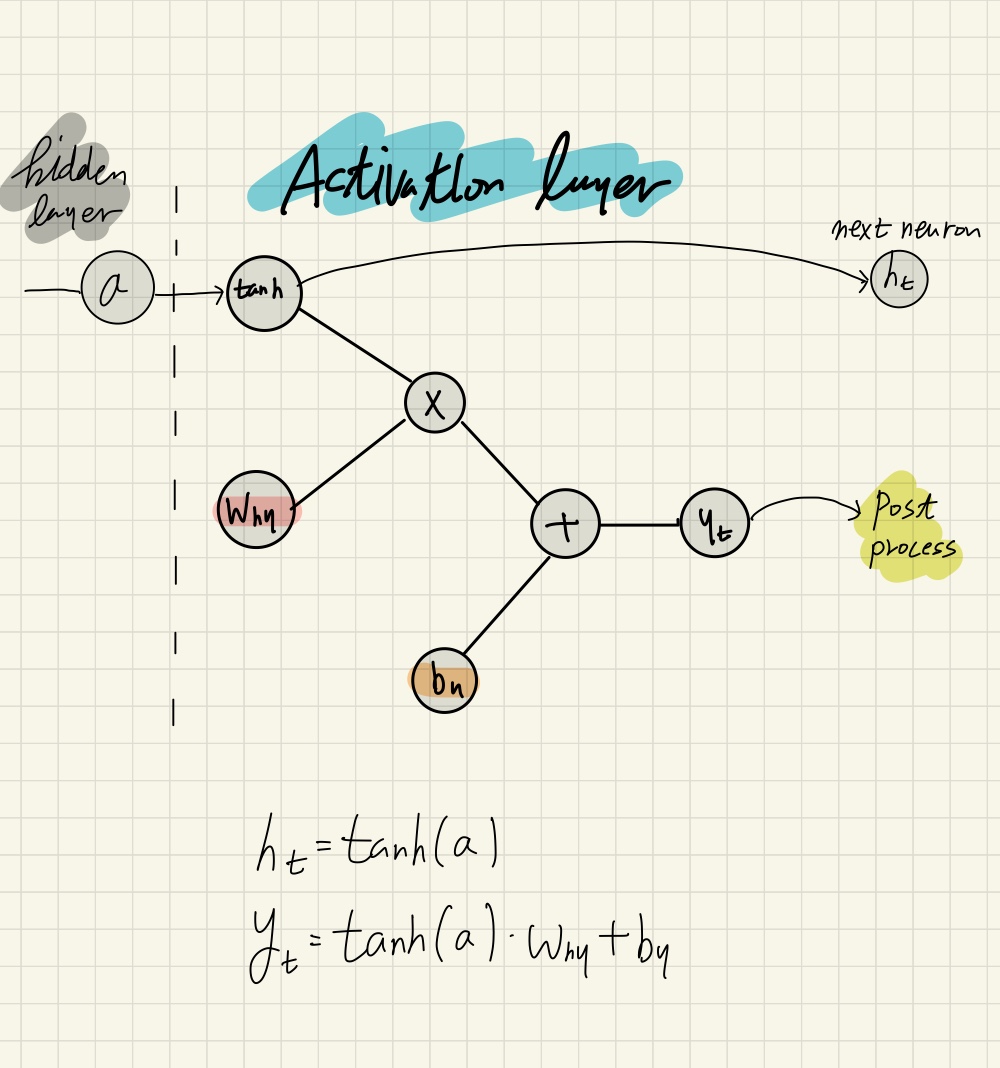
Figure5. Activation layer of min-char-rnn
후처리층(Postprocess layer)
후처리층은 소프트맥스 함수를 통해, 활성층의 출력 \(y_t\)를 \(p_t\)로 변형한다.
소프트맥스는 벡터를 원소들의 총 합이 1인 확률분포 형태로 변형한다.
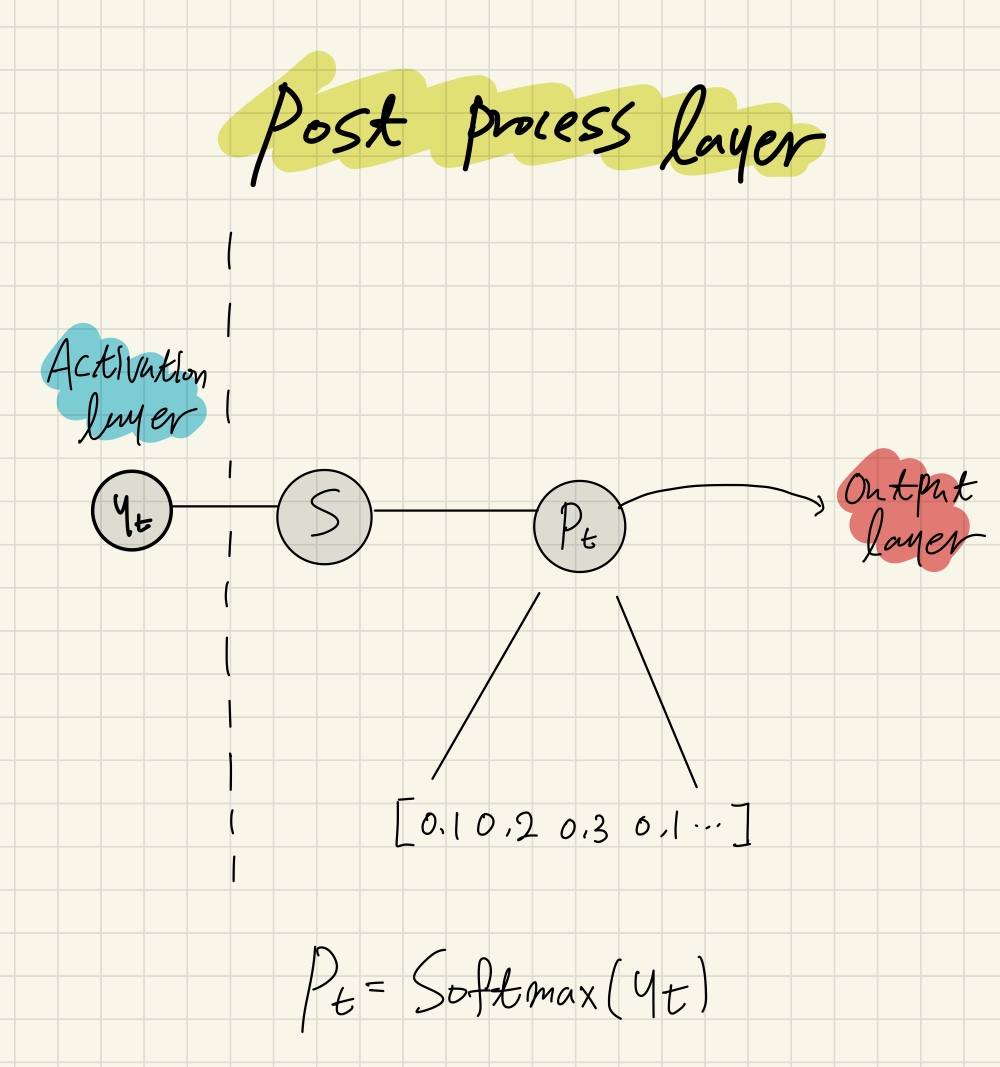
Figure6. Post process layer of min-char-rnn
출력층(Output layer)
후처리층에서 출력된 확률분포를 이용하여 문자들을 뽑아낸다.

Figure7. Output layer of min-char-rnn
=>다음 편에서는 min-char-rnn의 역전파에 대해 다루겠습니다.