Proper approach to use inline function in C&C++
19 May 2020인라인 함수(Inline function)
정의
인라인 함수는 inline키워드가 붙은 함수를 의미한다. 다음과 같은 방식으로 정의할 수 있다.
static inline int add(int a, int b){
return a+b;
}
Figure 1. 인라인 함수 정의
inline 키워드는 컴파일러에게 '컴파일 과정 중 이 함수가 인라인 처리(inlining)되기를 기대한다'라는 의미로 쓰인다. 여기서 인라인 처리란 함수의 호출 과정을 생략하고, 호출하는 부분에 함수의 구현체를 직접 삽입하는 컴파일 기법을 뜻한다.
용도
함수를 호출하기 위해서는 스택과 레지스터를 통해 인자를 전달하고, 스택프레임을 구성해줘야 해서 약간의 부하가 발생하는데, 인라인 처리를 하면 이를 제거할 수 있다는 장점이 있다. Figure1의 add와 같이 짧은 함수의 경우, 호출 부하(calling overhead)가 함수 실행의 전체 부하에서 큰 비중을 차지할 수 있기 때문에 인라인 처리를 하는 것이 바람직할 것이다.
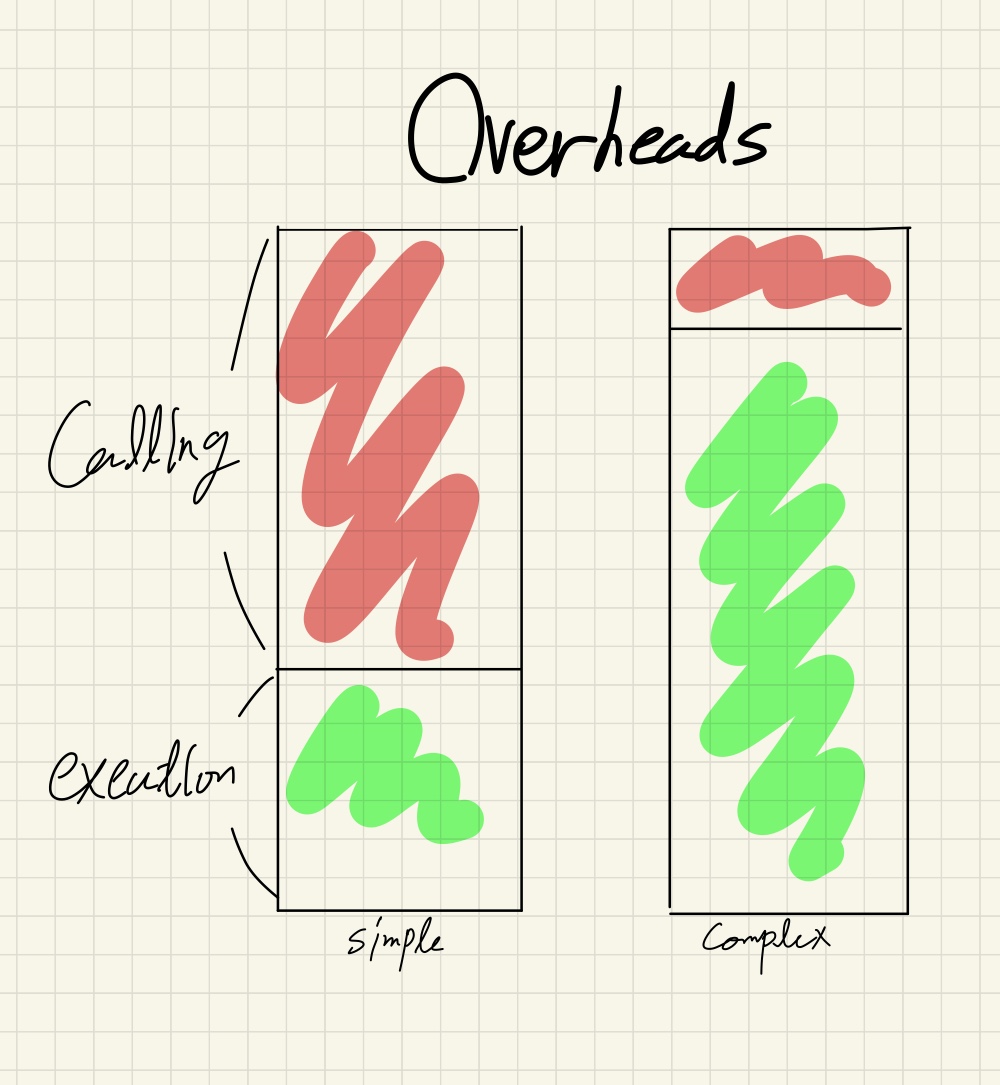
Figure2. 단순한 함수와 복잡한 함수에서 호출 부하가 차지하는 비중
특히 길이가 짧은 함수가 코드의 어떤 부분에서 여러 번 호출된다면, 인라인 처리로 반복되는 호출 부하를 없앨 수 있으므로 더욱 효과적이다.
인라인 처리의 단점은 바이너리의 크기가 커질 수 있다는 것이다. 예를 들어 어떤 인라인 함수가 코드의 여러 부분에서 사용되는 경우, 해당하는 모든 부분에 함수를 삽입해야 하기 때문에 바이너리의 전체 크기가 커질 수 있다.
그러나 앞서 설명했듯이 inline키워드는 컴파일러에게 인라인처리 되기를 바란다는 힌트이지, 강제하는 것이 아니다. 컴파일러가 이런 장단점 사이에서 스스로 판단을 하여, 인라인을 적용 할 수도 있고 안 할 수도 있다. 그러므로 길이가 짧다면 웬만하면 인라인 함수로 작성하고 컴파일러에게 판단을 맡기자.
용법
공통
일반적인 함수는 헤더 파일에서 선언하고, 소스 파일에서 정의하지만 인라인 함수는 이런 방식으로 작성할 수 없다(부록i 참조). 그러므로 인라인 함수는 헤더 파일에서 선언과 정의가 동시에 이루어 져야한다.
gcc를 사용할 때는 반드시 최적화 옵션(O1, O2, O3)등을 사용해야 한다. 그렇지 않으면 inline키워드를 사용해도 인라인처리를 해주지 않는다.
GCC does not inline any functions when not optimizing unless you specify the ‘always_inline’ attribute for the function, like this:
// from: https://gcc.gnu.org/onlinedocs/gcc/Inline.html
C
C에서 인라인 함수를 정의할 때는 헤더 파일에서 `static inline`을 통해 인라인 함수를 정의하는게 좋다. 다른 방법으로도 할 수 있지만, 이게 가장 바람직하다. 이유는 다음과 같다:
gcc에서는 함수 앞에 inline키워드만 있으면 심볼을 생성하지 않는다. 이유는 중복 정의(redefiniton error)가 발생할 수 있기 때문이다(부록ii 참조). 코드 사이에 그대로 삽입되는 인라인 함수에 심볼이 왜 필요한가 싶을 수 있지만, 코드에 따라 인라인 함수의 심볼이 필요할 때가 있다. 예를 들어 printf("%p", add) 에서는 함수 add의 심볼이 반드시 필요하다. 그런데 앞서 말했듯 inline 키워드만 있으면 심볼을 만들어주지 않는다. 그래서 이런 코드를 빌드하게 되면 ‘정의되지 않은 참조(undefined reference)’ 에러가 발생한다.
이런 버그들을 피하려면 C에서는 특별한 사유가 없을 때는 헤더 파일에 정적인 인라인 함수를 정의하는게 좋다.
C++
C++에서는 C와 조금 다르다. g++은 인라인 함수에 대한 심볼이 필요하다고 판단하면 weak심볼을 만들어 준다. weak심볼은 중복된 이름의 다른 심볼이 존재해도, 에러가 발생하는게 아니라 병합이 되기 때문에 중복 정의 에러는 발생하지 않는다. 따라서 C++에서는 static을 사용하지 않아도 C에서와 같은 ‘중복 정의’ 또는 ‘정의되지 않은 참조’ 에러는 발생하지 않는다.
그러나 여기서 유의해야 할 것은 실수로 인라인함수와 같은 이름이지만 다른 내용을 갖는 함수를 정의했을 때 문제가 발생할 수 있다는 것이다. 왜냐하면 프로그래머는 병합과정에서 어떤 함수가 살아남을지 알지 못하기 때문이다. 이 경우에 프로그램의 동작을 예측할 수 없게 된다.
예:
//from=> https://stackoverflow.com/a/10877261
source1.cpp:
inline int Foo()
{
return 1;
}
int Bar1()
{
return Foo();
}
source2.cpp:
inline int Foo()
{
return 2;
}
int Bar2()
{
return Foo();
}
FIgure2. 이 코드를 빌드하면 결과를 예측할 수 없다
Figure2를 빌드하면 하나의 Foo()만 살아남게 되는데, 그게 어떤 함수가 될지는 프로그래머가 알 수 없다. 이런 실수를 미연에 방지하려면 C++에서도 static을 붙이는 것을 추천한다.
참조)
-
https://gist.github.com/htfy96/50308afc11678d2e3766a36aa60d5f75
-
https://stackoverflow.com/questions/10876930/should-one-never-use-static-inline-function/16474078
이와 별개로 g++에서는 클래스 정의 안에 멤버 함수의 정의가 포함될 경우, 해당 멤버 함수를 인라인함수로 해석한다. 그렇기 때문에 멤버 함수의 길이가 짧다고 굳이 inline키워드를 붙일 필요는 없다. 그리고 클래스 내부에서 static 키워드는 전역에서와 갖는 의미가 전혀 다르기 때문에 위와 같은 목적으로 static을 붙이면 안된다.
종합
요약하면 C/C++에서 내가 생각하기에 최선의 인라인 함수 정의방법은 다음과 같다.
-
인라인 처리를 하고 싶은 함수가 있다면
inline키워드를 붙이자컴파일러가 알아서 처리를 해주겠지만, 명시적으로 키워드를 붙여주는게 좋다고 생각함
-
별다른 이유가 없다면
static을 앞에 붙이자에러가 발생하거나, 예상하지 못한 행동을 하게 될 수 있음
-
빌드 시 최적화 옵션을 킬 것
-
헤더파일에서 정의와 선언을 동시에 할 것
부록
1. 왜 인라인 함수는 선언과 분리를 따로 할 수 없는가
컴파일러에 들어가는 입력 파일을 번역 단위(Translation Unit, TU)라고 한다. 번역 단위는 전처리 과정을 거친 소스코드 이기 때문에 헤더 포함(header inclusion)과 매크로 치환(macro replacement)등이 모두 적용된 상태이다.
어떤 번역 단위에는 함수의 선언과 정의가 같이 존재할 수도 있고, 아닐 수도 있다. 번역 단위 내부에 선언만 있고, 정의가 존재하지 않는다면, 컴파일러는 함수의 주소를 링크 과정에서 채울 수 있도록 심볼만 만들어 놓는다. 그러면 나중에 링커가 함수의 구현체를 찾아서 연결시켜준다.
다음 코드로 이해를 돕겠다.
// test.c
#include <stdio.h>
#include "add.h"
int main(){
printf("%d",add(3,4));
}
// add.h
int add(int a, int b);
// add.c
#include "add.h"
int add(int a, int b){
return a + b;
}
Figure3. 간단한 분할 컴파일 예제
Figure3를 컴파일 할 때, (test.c/add.h/stdio.h/…) 그리고 (add.c/add.h) 각각 두 번역 단위가 존재할 것이다. 전자에는 add함수의 선언만 존재하고, 정의는 후자에 포함돼있다. 따라서 각 번역단위를 gcc로 컴파일 하고 readelf로 심볼정보를 확인해 보면, 전자의 오브젝트 파일에는 NOTYPE add 심볼이, 후자의 오브젝트 파일에는 FUNC 타입의 add심볼이 있는 것을 확인할 수 있다. 링크 과정에서는 후자에서 함수의 구현체를 찾아 전자의 NOTYPE를 해소(resolve)한다.
만약 함수의 정의가 어느 번역 단위에도 존재하지 않는다면, 정의되지 않은 참조에러가 발생하게 된다.
$ readelf -s test.o
Symbol table '.symtab' contains 13 entries:
Num: Value Size Type Bind Vis Ndx Name
0: 0000000000000000 0 NOTYPE LOCAL DEFAULT UND
1: 0000000000000000 0 FILE LOCAL DEFAULT ABS test.c
2: 0000000000000000 0 SECTION LOCAL DEFAULT 1
3: 0000000000000000 0 SECTION LOCAL DEFAULT 3
4: 0000000000000000 0 SECTION LOCAL DEFAULT 4
5: 0000000000000000 0 SECTION LOCAL DEFAULT 5
6: 0000000000000000 0 SECTION LOCAL DEFAULT 7
7: 0000000000000000 0 SECTION LOCAL DEFAULT 8
8: 0000000000000000 0 SECTION LOCAL DEFAULT 6
9: 0000000000000000 45 FUNC GLOBAL DEFAULT 1 main
10: 0000000000000000 0 NOTYPE GLOBAL DEFAULT UND _GLOBAL_OFFSET_TABLE_
11: 0000000000000000 0 NOTYPE GLOBAL DEFAULT UND add #symbol required defining
12: 0000000000000000 0 NOTYPE GLOBAL DEFAULT UND printf
$ readelf -s add.o
Symbol table '.symtab' contains 9 entries:
Num: Value Size Type Bind Vis Ndx Name
0: 0000000000000000 0 NOTYPE LOCAL DEFAULT UND
1: 0000000000000000 0 FILE LOCAL DEFAULT ABS add.c
2: 0000000000000000 0 SECTION LOCAL DEFAULT 1
3: 0000000000000000 0 SECTION LOCAL DEFAULT 2
4: 0000000000000000 0 SECTION LOCAL DEFAULT 3
5: 0000000000000000 0 SECTION LOCAL DEFAULT 5
6: 0000000000000000 0 SECTION LOCAL DEFAULT 6
7: 0000000000000000 0 SECTION LOCAL DEFAULT 4
8: 0000000000000000 20 FUNC GLOBAL DEFAULT 1 add #compiled function
Figure4. 심볼들
일반적인 함수는 위와 같은 방식으로 컴파일될 수 있지만 인라인 함수는 이렇게 할 수 없다. 왜냐하면 인라인처리를 하려면 번역단위를 컴파일 하면서 인라인함수를 컴파일하고 호출 부분에 코드를 삽입해야 하는데, 함수의 정의가 다른 번역 단위에 존재하면 컴파일할 인라인 함수의 코드를 찾을 수 없기 때문이다. 그래서 인라인 함수는 정의와 선언이 같이 존재해야 한다.
2. static이 없으면 왜 중복 정의 에러가 발생할 수 있는가
중복 정의 에러는 전역(global) 심볼들 중 중복되는 이름의 심볼이 존재할 때 발생한다. 헤더파일에 전역 함수의 정의를 포함하게 되면, 그 헤더를 포함한 모든 번역단위에서 해당 함수를 컴파일하고 심볼을 만든다. 이렇게 동일한 이름의 전역 심볼이 여러개 생기면 최종 링크 과정에서 중복 정의 에러가 발생한다. static 키워드를 붙이면 심볼의 스코프가 지역(Local)로 조정되기 때문에 이런 에러를 피할 수 있다.